
Intelligence Artificielle en médecine: existe-t-il une "exception digitale" qui fausse les résultats ?
En 2016, Geoffrey Hinton, l’un des inventeurs des réseaux de neurones artificiels, affirmait qu’il ne faudrait que 5 ans à 10 ans à l’intelligence artificielle pour supplanter les radiologues. La déclaration a fait date et a influencé le débat public. A tel point, que certains se sont aventurés à demander la fin de la formation de médecins radiologues.
Il est un fait que l’imagerie est le champ d’activité médicale le plus propice au développement d’algorithmes issus de l’apprentissage profond. Cette méthode d’apprentissage machine est à l’origine des succès spectaculaires obtenus par plusieurs équipes de chercheurs à travers le monde. Depuis environ 3 ans, les annonces de systèmes autonomes capables d’interpréter des images médicales avec « plus d’efficacité que des médecins expérimentés » se multiplient.
Qu'en est-il réellement? C'est la question que s'est posée un groupe de radiologues de l'université de Séoul en Corée du Sud. Bien moins médiatisés que Geoffrey Hinton ou que les chercheurs de GOOGLE, ils se sont penchés sur la qualité scientifique des études impliquant l’IA en imagerie médicale. Ils ont examiné 516 articles publiés dans des revues scientifiques en 2018 et livrent leurs conclusions dans le numéro de mars 2019 du Journal Coréen de Radiologie.
Quelles informations étaient recherchées à l'intérieur des 516 articles?
Les auteurs ont cherché à savoir si la méthodologie des études publiées en intelligence artificielle était en adéquation avec les principes scientifiques de la recherche clinique.
Ils rappellent, dans leur introduction, que la validation d’une innovation peut se faire pour évaluer 3 effets potentiels: la performance diagnostique, l’effet sur le pronostic médical et l’efficacité sociale, c’est-à-dire le rapport entre les coûts et les bénéfices escomptés.
En se référant aux règles habituelles de la recherche clinique, ils définissent les conditions que devraient respecter les chercheurs en intelligence artificielle médicale. Tout d'abord, il faudrait disposer, pour effectuer des tests de terrain, de données différentes de celles ayant servi à entraîner les machines. Ces données doivent être en nombre suffisant et devraient provenir de patients nouveaux, recrutés de façon prospective, dans des centres différents de celui qui a conçu le système d'IA. Enfin, elles doivent être représentatives des variations démographiques des malades et de la variabilité de leurs situations cliniques.
_____________________________________________________________________________________________________________________________________
Les radiologues de Seoul se réfèrent à quelques règles fondamentales de la recherche clinique. Quelles sont-elles?
Des groupes homogènes de malades
En recherche clinique, les patients sont sélectionnés pour participer. En effet, pour obtenir un résultat interprétable, il faut comparer entre elles des personnes comparables. Par exemple, si on veut tester un nouveau traitement anti-hypertenseur, il faut organiser une comparaison avec un ancien médicament entre des groupes de malades qui se ressemblent. Toutes les personnes doivent bien entendu être atteinte d'hypertension artérielle. Mais certains éléments pourraient fausser les résultats: l'âge, le sexe, d'autres maladies comme le diabète par exemple. Pour que la comparaison soit fiable, les 2 groupes doivent comprendre la même proportion d'hommes et de femmes, de diabétiques etc. Ainsi, la recherche peut se faire dans des conditions proches de la réalité et donner des résultats fiables qui seront ensuite applicables dans "la vraie vie".
Etude prospective
Une étude prospective est une étude qui inclue des personnes sélectionnées. Elle s'oppose à l'étude rétrospective qui analyse les dossiers clos de malades déjà soignés. Pour étudier l'effet d'une technique médicale innovante ou d'un nouveau médicament, il faut organiser une étude prospective. Ainsi, il est possible de recruter les groupes homogènes dont nous avons parlé plus haut et d'organiser un suivi très précis des malades inclus. L'étude prospective est un élément essentiel de la fiabilité de l'évaluation de l'innovation en médecine.
Etude multi-centrique
Une étude ayant lieu dans plusieurs centres. Une étude qui n'a qu'un seul centre comprend toujours un biais de recrutement, le premier d'entre eux est géographique. D'une ville à l'autre, vivent des personnes différentes. Le fait d'impliquer plusieurs centres permet de limiter ces biais de recrutement et d'augmenter les chances d'obtenir un groupe de personnes participantes représentatif de la population générale.
_____________________________________________________________________________________________________________________________________
Les auteurs constatent que les chercheurs en intelligence artificielle s’affranchissent des règles de la recherche clinique et créent une véritable «exception digitale». En effet, les informaticiens évaluent la performance de leurs algorithmes à partir de données tests. Mais celles-ci sont extraites par sélection aléatoire à l’intérieur de la base de données qui a servi à entraîner la machine (Sur ce point, voir nos articles de la série "COMPRENDRE L'IA EN MEDECINE"). Il n’existe donc pas de validation extérieure, « dans la vraie vie », contrairement aux pratiques habituelles de la recherche médicale.
Pour comprendre l'ampleur de ce phénomène, les radiologues de Séoul ont donc analysé 516 études publiées en 2018. Seulement 31, soit 6% avaient fait l’objet d’une validation extérieure. Mais aucune de ces 31 ne remplissait les conditions méthodologiques habituelles de la recherche clinique à savoir l’organisation d’une cohorte de suivi, le caractère prospectif et l’aspect multi-centrique.
DISCUSSION DES AUTEURS
Leur analyse des 516 articles confirme ce que d’autres avant eux avaient détecté: la plupart des travaux publiés en IA pour imagerie médicale ont un faible niveau de preuves. Elles correspondent à des études de faisabilité technique et n’ont pas la méthodologie requise pour démontrer une efficacité dans le monde réel.
COMMENTAIRE DE MEDECINE ET ROBOTIQUE
L'article des radiologues coréens est bienvenu. Ils montrent que le mouvement de l’intelligence artificielle médicale se fait à contre-courant des principes de la recherche médicale. Une "exception digitale" s'est constituée. Mais elle n'a aucune justification scientifique.
La médecine est en effet une science biologique et sociale. Biologique, car le corps humain est un assemblage de cellules. Leur dysfonctionnement est à l'origine des maladies. Sociale, car la recherche médicale doit prendre en compte la diversité humaine. Pour cela, elle doit sélectionner des groupes représentatifs de la population générale. Tout phénomène observé chez un individu (par exemple l’effet d’un médicament ) est l’aboutissement de processus complexes au cours desquels cellules et organes interagissent avec leur environnement. Il en résulte qu'en médecine, il est presque impossible d’obtenir un résultat d’expérience fiable si les tests ne sont pas effectués au plus près des conditions réelles. C'est la raison pour laquelle la recherche clinique est organisée autour d'une méthodologie stricte et contraignante. Le vivant a donc ceci de particulier, qu’une technologie ne peut y être introduite ex cathedra. On "n’implémente" pas une technologie dans l’organisme comme on charge un logiciel.
Ainsi, la répercussion médiatique des résultats des expérimentations d’intelligence artificielle médicale est totalement contre-intuitive. C'est ce qui a conduit les radiologues de Séoul à mener leur analyse. Comme ils le montrent, l’intelligence artificielle médicale en est encore au stade de l’étude préliminaire.
Il ne s’agit certainement pas de minimiser l'impact de la technologie sur la médecine. Mais, sous peine de subir les plus grands échecs, l’IA doit s'intégrer dans une démarche scientifique d’évaluation de terrain. Les compétitions spectacles, telle celle organisée en Chine l'an passé entre un groupe de radiologues et une IA qui s'affrontaient pour interpréter des scanners cérébraux ne peuvent en tenir lieu.
Les échecs existent déjà. Le système d'intelligence artificielle WATSON d’IBM, qui a été annoncé en 2013 comme une révolution du diagnostic médical, ne s'est toujours pas implanté et est en grande difficulté commerciale. Cet exemple devrait encourager à davantage de mesure et, surtout, de réalisme, toutes celles et tous ceux qui prophétisent le remplacement rapide des médecins par des systèmes automatisés. Il est parfaitement irresponsable, comme cela a été fait récemment, de réclamer la diminution du nombre de médecins en formation ou la suppression pure et simple de telle ou telle spécialité en se basant sur un niveau de preuves aussi bas. Prétendre que les médecins vont disparaitre prochainement pour être remplacés par une IA et que les malades seront soignés par des robots intelligents et autonomes est une absurdité.
Avant de vouloir se projeter sur les effectifs et de produire des prédictions chiffrées toutes plus fausses les unes que les autres, il conviendrait de définir le portrait robot de la médecine du XXIe siècle. Comment sera-t-elle exercée? Quelles maladies rencontrera-t-elle? Concernant le futur de la profession médicale, tout au plus peut-on écrire que certaines tâches seront automatisées et que les médecins devront, à l’avenir, être plus polyvalents pour s’adapter. A ce jour, très franchement, il est difficile d’aller plus loin dans la prospective.
REFERENCES
Article des radiologues de Seoul
Design Characteristics of Studies Reporting the Performance of Artificial Intelligence Algorithms for Diagnostic Analysis of Medical Images: Results from Recently Published Papers par Dong Work Kim et Coll.
Sur la recherche clinique
L'article de WIKIPEDIA est très clair et bien renseigné
https://fr.wikipedia.org/wiki/Essai_clinique
Les rubriques du BLOG consacrés à l'IA médicale
COMPRENDRE L'INTELLIGENCE ARTIFICIELLE EN MEDECINE
UNE INTELLIGENCE ARTIFICIELLE POUR LIRE LES PENSEES?
Sera-t-il possible, un jour, de "lire les pensées» ? L’expérience publiée dans la revue Nature/Scientific Report en janvier 2019 par une équipe de chercheurs de New York, nous en rapproche peut-être. Mais, si les scénarios des films de science-fiction restent très éloignés, les interfaces humain /machine qui permettent de piloter des drones, des robots ou des ordinateurs par la pensée ainsi que les neuroprothèses d’aide à la parole pour personnes paralysées pourraient bien connaître d’intéressants progrès grâce à l'intelligence artificielle.
Essayons ensemble de comprendre le travail des chercheurs et pénétrons l'univers passionnant de la "lecture de la pensée".
QUELQUES INFORMATIONS PRÉALABLES POUR COMPRENDRE
Qu'est-ce qu'un électro-encéphalogramme (EEG)?
Le cerveau produit des ondes électriques qui correspondent à l'activité des cellules qui le composent: les neurones. Ces ondes existent en permanence, que ce soit pendant le sommeil ou en éveil. Il est possible de les enregistrer, c'est l'électro-encéphalogramme. Cet enregistrement est un examen médical courant très utilisé en neurologie et en médecine du sommeil.
Il existe plusieurs façons de le recueillir. La plus répandue est l'EEG dit de surface. Des électrodes sont placées à la surface du crâne. Le signal vient du cerveau et doit traverser la boîte crânienne pour atteindre l'électrode d'enregistrement.
La méthode invasive consiste à introduire les électrodes d'enregistrement sous la boîte crânienne, à la surface où à l'intérieur du cerveau. Il s'agit d'une procédure de neuro-chirurgie utilisée pour traiter certaines maladies comme l'épilepsie résistante aux médicaments. Les chercheurs New Yorkais ont choisi une méthode invasive avec des électrodes placées à la surface du cerveau.
QUELLE A ETE L'EXPERIENCE REALISEE PAR LES CHERCHEURS?
L'étude a inclus 5 patients pris en charge en neurochirurgie pour ablation des foyers épileptiques dans le but de traiter une épilepsie résistante aux médicaments. Pour ce type d’intervention, les neurochirurgiens implantent des électrodes à la surface du cerveau. Les chercheurs ont capté le signal électro-encéphalogramme émis par ces électrodes pour réaliser leur expérience.
Ce n’est pas la première fois que ce type d’expérience est organisé par des chercheurs qui s’intéressent à l’interface homme /machine. En effet, tout système de contrôle d'objet "par la pensée" (un drone, un robot, un ordinateur) repose sur la captation des ondes cérébrales et l'enregistrement d'un EEG. La présence de sondes dans le cerveau offre les meilleures conditions pour recueillir un EEG et par là, les meilleures conditions expérimentales.
Rappelons, pour celles et ceux qui ne seraient pas familiers des études cliniques que ce type d'expérience est strictement réglementé que ce soit en Europe ou aux Etats-Unis. Chaque patient a signé un consentement d'inclusion dans l'étude. Par ailleurs, le cerveau, bien que centre neurologique, ne contient pas de récepteurs sensitifs. Il ne ressent donc pas la douleur. Dans ce type d'expérience, il n'y a pas d'intervention sur le cerveau. Les chercheurs se contentent de recueillir un signal EEG. C'est le signal EEG qui subit une transformation. L'expérience est donc sans risque médical et sans douleur pour les personnes participantes.
L'expérience a consisté à faire écouter à chacun des 5 patients un texte lu par une personne extérieure pendant une durée 30 min. Pour être certain que le patient avait bien entendu, on interrompait la lecture à intervalle régulier et on faisait répéter la dernière phrase.
Les chercheurs ont enregistré l’électro-encéphalogramme émis par le cortex auditif pendant l’écoute de la lecture.
C’est à partir de cet enregistrement qu’ils ont reconstitué la parole.
Evaluation de l'intelligibilité
Seulement une partie du texte écouté a été reconstruite, 8 phrases et des chiffres. L’intelligibilité de la parole reconstruite a été évaluée au moyen de tests objectifs qui ont porté sur les 8 phrases et de tests subjectifs qui ont porté sur les chiffres.
Evaluation subjective. Les chercheurs ont demandé à 11 personnes d’écouter la reconstruction des chiffres dans un environnement calme. Chaque chiffre était écouté une seule fois. Les personnes participantes avaient pour consigne, soit de reproduire le chiffre si il était compréhensible, soit, dans le cas contraire, d'indiquer qu’il n’était pas intelligible. Il fallait également donner le genre de l’orateur ou de l’oratrice. (Le texte écouté par les patients était lu par 4 personnes, 2 femmes et 2 hommes). Enfin, il fallait attribuer une note de qualité à la parole reconstruite sur une échelle de 1à 5.
Evaluation objective. Les chercheurs ont soumis les enregistrement à un algorithme de mesure de l’intelligibilité qui rendait une note comprise entre 1 (très mauvais) et 10 (très bien). Cet algorithme est utilisé de manière courante pour évaluer l’intelligibilité des technologies de synthèse de la parole.
Principaux résultats
Les chercheurs ont donc utilisé l’électro-encéphalographie invasive pour mesurer l’activité des neurones du cortex auditif de 5 personnes pendant qu’elles écoutaient un texte lu par d’autres. La reconstruction n’a pas été faite sur l’intégralité du texte mais sur des parties. L’évaluation objective a porté sur l'écoute de la reconstruction de 8 phrases (40 s au total) et l’évaluation subjective sur celle de 40 sons de chiffres de zéro à 9.
4 méthodes au total ont été testées pour reconstruire la parole, dont 2 utilisant l'apprentissage profond. Parmi elles, c’est celle basée sur l’entrainement par apprentissage profond d'un vocodeur qui s’est avérée être la plus efficace. (Un vocodeur est un dispositif électronique de traitement du signal sonore utilisé dans les métiers du son).
Evaluation subjective. Les performances des 4 méthodes étudiées s’échelonnent de 45 à 75% pour l’intelligibilité, la note de qualité de 2.1 à 3.4 /5 et l’identification du genre de l’orateur de 32% à 80%. Pour chacun de ces 3 résultats, la meilleure performance est obtenue par le vocodeur entraîné par deep learning.
Evaluation objective. Elle confirme les résultats de l’évaluation subjective avec un résultat significativement de meilleur qualité pour le vocodeur entraîné par deep learning.
Discussion des auteurs
Les auteurs mettent en avant les résultats suivants. Parmi les méthodes étudiées, celle basée sur le vocodeur entraîné par apprentissage profond a donné les meilleurs résultats. La qualité de la reconstruction est dépendante du nombre d’électrodes implantées dans le cerveau.
Leur conclusion est la suivante. « Nous présentons un cadre général pouvant être utilisé par les technologies de neuroprothèses parlées et pouvant aboutir à des reconstructions intelligibles de la parole à partir du cortex auditif. Ceci peut représenter un pas vers la prochaine génération d’interface homme-machine et vers des moyens de communication naturels pour des patients souffrant de paralysies et de locked-in syndrome ».
COMMENTAIRES DE LA REDACTION DE MEDECINE-ET-ROBOTIQUE
La récupération des ondes émises par l’activité électrique du cerveau pour interagir avec des objets technologiques fait l’objet d’un intérêt croissant. Les scènes de « lecture des pensées » de nos films de science-fiction vont-elles prendre vie prochainement? Plusieurs médias n’ont pas hésité à l’affirmer à la lecture de l'article de Scientific Report. La réalité n'est pas aussi spectaculaire mais il n'en demeure pas moins que les résultats acquis pas les chercheurs ouvrent de grandes perspectives, en interface humain/machine mais aussi et surtout en médecine.
Où en sont réellement les chercheurs?
Précisons, tout d'abord, si besoin était, qu'il n'y a pas eu, dans ce travail, de création d'un système d'IA autonome capable de lire les pensées. Cette interprétation de la recherche est fausse. Il ne s’agit que d’une extrapolation destinée à faire le buzz sur les réseaux sociaux. A cet égard, remarquons que les chercheurs n'en parlent à aucun moment dans leur article.
Nous avons reproduit leur conclusion. Pour les auteurs, l'étude a montré l’intérêt des techniques d’IA, plus précisément l’apprentissage profond, dans le traitement du signal EEG pour reconstruire la parole. Rien de plus.
Ajoutons que l’expérience ne correspond pas à une lecture passive de l’activité cérébrale des sujets. Une tâche (l’écoute d’un texte) a été demandée aux participants. Cette tâche mobilise une zone unique et bien ciblée du cerveau, le cortex auditif. C’est assez différent de l’acte de penser librement par soi-même. Nous n’avons pas encore les moyens technologiques d’enregistrer à distance les pensées d’une personne et de les retraduire en paroles!
Cette recherche est, certes, une avancée scientifique et technique mais, à ce jour, il est très prématuré de parler de technologie aboutie.
Il n’est bien entendu pas interdit de se projeter et d’imaginer les évolutions futures. A l’avenir, peut être, pourrons-nous lire les pensées. Mais affirmer que cela a été réalisé par cette étude est faux. Les chercheurs ont simplement montré que l'intelligence artificielle pouvait être efficacement utilisée pour améliorer les techniques actuelles d'interaction cerveau-machine.
Il reste maintenant à concrétiser cela dans des applications pratiques.
Quel peut être l’avenir de l’interface cerveau-machine?
De premières applications sont déjà sur le marché. Il s’agit de casques qui permettent de piloter des objets robotisés par la pensée, des drones par exemple. Ils sont basés sur le même principe de recueil de l’EEG traduit secondairement en commande motrice.
Mais les applications les plus intéressantes sont médicales. Ces recherches suscitent de grands espoirs pour le handicap. En effet, l'un des objectifs des chercheurs est d'aboutir à la production de neuro-prothèses qui permettraient de rendre la communication avec l'extérieur à des personnes paralysées ayant perdu l'usage de la parole mais qui s'entendent penser. Ces prothèses recueilleraient le signal auditif pour le retraduire en son parlé. Un enthousiasmant progrès médical en perspective!
Référence
https://www.nature.com/articles/s41598-018-37359-z
POUR COMPLETER SON INFORMATION
SUR LES INTERFACES CERVEAU/MACHINE:
Une synthèse datée de 2015 par les chercheurs de l'INSERM qui expose clairement les principes techniques
https://www.inserm.fr/information-en-sante/dossiers-information/interface-cerveau-machine-icm
SUR LA RECONSTRUCTION DE LA PAROLE PAR EEG
En anglais et en accès libre.
Un article général de la revue Science accompagné d'enregistrements audio de paroles reconstruites (dont un de l'étude que nous avons présenté).
https://www.sciencemag.org/news/2019/01/artificial-intelligence-turns-brain-activity-speech
MICRO-ROBOTS CIRCULANTS: UN TOURNANT POUR LA MEDECINE? PREMIERE PARTIE
Le journal Science Robotics a publié dans son édition du 22 novembre 2017, le résultat d'une série d'expériences menées conjointement par des chercheurs chinois et britanniques des universités de Hong Kong, Manchester et Edimbourg. Ils ont réussi à fabriquer des robots à partir d'une micro-algue qui a été recouverte de nanoparticules magnétiques. Ces Robots Magnétiques Bio-Hybrides, capables de circuler dans les liquides biologiques (sang, urine, liquide gastrique) sont facilement repérables par imagerie médicale, biodégradables et peu toxiques. Ils pourraient être utilisés pour réaliser du traitement ciblé, en particulier dans les cancers. De surcroit facile à fabriquer, ils pourraient être produit à large échelle à moindre coût.
La possibilité de fabriquer des micro-robots médicaux téléguidés capables de circuler dans le corps humain pour en atteindre les endroits les plus inaccessibles est à l’étude depuis plusieurs années. Mais les chercheurs étaient jusqu'à présent confrontés aux défis majeurs de la biodégradabilité et de la toxicité pour les organismes biologiques. Les auteurs annoncent avoir trouvé des solutions techniques qui pourraient bien s'avérer décisives et ouvrir la voie aux applications cliniques.
Nous présentons et commentons cette recherche dans un article en deux parties.
PREMIERE PARTIE: LE RESUME DE LA PUBLICATION DES CHERCHEURS.
Comment est fabriqué le robot ? Comment fonctionne -t-il?
LA COMPOSITION DU ROBOT
Pour fabriquer le robot, l’équipe de recherche a transformé une algue, structure biologique, en corps magnétique. L’expression robot bio-hybride a été choisie pour le dénommer car il associe 2 composés, l’un vivant et l’autre minéral.
La première minute de la video ci-dessous nous le montre en mouvement dans de l'eau lors d'une expérience de laboratoire. Comme on peut le voir il a la forme d'un petit vers, d'environ 100μm.
LE COMPOSE VIVANT: LA MICRO-ALGUE Spirulina Platensis.
Les chercheurs en cancérologie connaissent déjà cette micro-algue car elle contient un composé capable de tuer les cellules dans la leucémie, le carcinome à petites cellules ou encore l'adénocarcinome du colon. Cette toxicité de la micro-algue est spécifique, c’est à dire qu’elle agresse les cellules cancéreuses sans endommager les cellules normales.
L’algue possède 2 autres propriétés intéressantes exploitées par les chercheurs. Elle est naturellement fluorescente, ce qui permet de la repérer facilement par imagerie médicale. La taille de son corps peut être modifiée et ajustée pour répondre au mieux aux impératifs de la fabrication du robot.
LE COMPOSE MINERAL: LA MAGNETITE ( FORMULE: Fe3O4)
Pour fabriquer le robot, les chercheurs ont enduit les algues de nanoparticules de Fe3O4. Elles se lient aux molécules biologiques de surface sans altérer leur structure. La magnétite capte l’énergie magnétique, transformant l’algue en petit robot téléguidé.
Le Fe3O4 est neutre biologiquement, c’est à dire qu’il est peu agressif pour les cellules humaines. Ses propriétés permettraient aussi d’ajouter de petites structures capables de se lier à des molécules pharmacologiques. La fonction du nanorobot pourrait ainsi évoluer vers la thérapeutique ciblée.
QUELS ETAIENT LES PROBLEMES A RESOUDRE POUR LES CHERCHEURS?
Premièrement, pour naviguer dans les liquides biologiques, il est nécessaire de pouvoir suivre le déplacement du robot en temps réel. Pour cela il faut disposer de procédés d’imagerie médicale non invasive. Les chercheurs ont utilisé l’IRM (Imagerie par Résonance Magnétique) et la fluorescence naturelle de l’algue Spilurina Platensis.
Deuxièmement, ces robots doivent être biodégradables c’est-à-dire, soit s'auto-détruire, soit être éliminé par l’organisme sans causer d’effets secondaires.
Troisièmement, l’essaim de micro-robots doit pouvoir circuler dans le corps sans endommager les cellules normales.
COMMENT DEPLACER LE MICRO-ROBOT ?
Son mouvement est hélicoïdal. Il ne se déplace pas seul mais en grand nombre sous forme d'essaim de près d’un million de robots.
L’essaim est piloté grâce à un aimant placé à distance du corps de l'animal. Les caractéristiques physiques du champ magnétique envoyé à l'essaim sont déterminées avec précision selon les propriétés magnétiques du robot, sa taille et sa forme. Pour la bonne compréhension des expériences présentées ici, il faut souligner que le champ magnétique qui mobilise le robot n'est pas le même que celui utilisé pour faire l’Imagerie par Résonance Magnétique.
LE DEPLACEMENT AU SEIN DES LIQUIDES BIOLOGIQUES
Les chercheurs ont obtenu des résultats in vitro très satisfaisants dans plusieurs liquides biologiques: eau, sang, liquide gastrique, urine, huile de cacahuète visqueuse.
Mais seul le liquide gastrique a été testé in vivo chez le rat. Le robot est superparamagnétique, ceci veut dire qu’il cesse d’être magnétique lorsqu’on arrête le champ énergétique. Ainsi, les robots ne peuvent pas se regrouper et former des conglomérats qui viendraient obturer les vaisseaux sanguins et provoquer des accidents médicaux, ce qui est essentiel pour assurer la sécurité de futures applications cliniques.
IN VITRO ET IN VIVO
IN VITRO: expériences réalisée en milieu artificiel, en laboratoire
IN VIVO: expériences réalisées dans l'organisme vivant
COMMENT ONT ETE CONDUITES LES EXPERIENCES DE DEPLACEMENT ?
Les expériences de télé-guidage ont été menées dans l'estomac chez le rat, en laboratoire. A ce jour, il n'y a pas eu d'essai chez l'être humain.
Après l’avoir introduit dans l’estomac du rat, les chercheurs ont repéré l’essaim par IRM. Ils ont choisi de lui faire traverser l’estomac jusqu'à la zone sous-cutanée recouvrant le ventre de l’animal. Pour cela ils ont appliqué un champ magnétique depuis un aimant situé à proximité.
Deux imageries à 5 min et 12 min ont été réalisées. Elles ont chacune repéré l’essaim à la position voulue.
Les chercheurs ont cependant tenu à prouver que le déplacement était bien provoqué par le champs magnétique externe. En effet, d’autres causes aurait pu faire bouger le robot, le mouvement naturel du tube digestif - ou péristaltisme- par exemple.
Pour le vérifier, ils ont introduit un essaim de robots dans un groupe contrôle, sans appliquer de champ magnétique. L’essaim n’a pas bougé leur donnant la preuve recherchée.
Les auteurs ont ainsi pu conclure qu’il était possible de propulser un essaim de robot bio-hybride au travers d’un estomac de rat et de suivre son déplacement par imagerie par résonance magnétique.
LA BIO-DEGRADATION.
Elle est dépendante des propriétés de Fe3O4 et du temps mis à enduire l’algue. Les temps sont choisis en fonction de l’application voulue: imagerie, thérapeutique..
Les temps de dégradation décrit dans les expériences vont de 24 à 72 h mais certains micro-robots persistent jusqu’à 168h si l’enduit est trop épais.
LA TOXICITE DU ROBOT-BIOHYBRIDE ENVERS LES CELLULES CANCEREUSES
Dans les expériences menées par les chercheurs, le robot a été mis en contact avec des cellules humaines normales ( fibroblastes) puis avec des cellules de cancer du foie et de l’utérus. La cytotoxicité s’est avérée faible pour les cellules normales avec 80 % des cellules viables à 48h et élevée pour les cellules cancéreuses avec, à 48h d’exposition, 10% de survivantes dans le cancer du col de l’utérus et 50% dans le cancer du foie.
Le robot étant composé de l’algue et de magnétite (Fe3O4), il était important de vérifier la provenance de la toxicité. Les chercheurs ont donc mené des expériences avec Fe3O4 seul. La toxicité de celui-ci est apparue marginale. C’est donc bien l’algue qui est toxique pour le cancer. Mais ces effets cytotoxiques apparaissent moins importants si la couche de Fe3O4 est plus épaisse.
La toxicité de l’algue Spirulina Platensis envers les cellules cancéreuses est en fait déjà connue des scientifiques. Elle est provoquée par l’un des composants de sa membrane corporelle dénommé C-phyocyanine. Il interfère avec des mécanismes biologiques qui n’existent pas dans la cellule normale, entraînant la mort des cellules cancéreuses tout en préservant les cellules normales.
SUITE DE CET ARTICLE: LE COMMENTAIRE DE LA REDACTION DE MEDECINE ET ROBOTIQUE
LES MICRO-ROBOTS CIRCULANTS VONT-ILS OUVRIR UNE NOUVELLE PAGE DE L'HISTOIRE DE LA MEDECINE?
Référence:
Multifunctional biohybrid magnetite microrobots for imaging guided therapy
VIdeo de présentation de l'étude (en anglais) sur le site de Science Robotics
http://www.sciencemag.org/news/2017/11/robot-made-algae-can-swim-through-your-body-thanks-magnets
COMPRENDRE L'IA EN MEDECINE N°1. GOOGLE PREDIT LE RISQUE CARDIO-VASCULAIRE
ll ne se passe plus de mois sans qu'un nouveau logiciel issu de l'intelligence artificielle ne soit déclaré "meilleur que les médecins" et présenté au public. Que signifie vraiment cette formule? Peux-t-on réellement implanter des systèmes automatiques en lieu et place des médecins?
Dans cette rubrique nous rendons compte d'études dont les résultats sont généralisables à l'ensemble de l'intelligence artificielle médicale. En décrivant les faits scientifiques, nous espérons mettre à disposition du plus grand nombre des informations de fond permettant à chacune et chacun d'appréhender le débat de société entourant l'IA médicale.
GOOGLE a récemment annoncé avoir développé une intelligence artificielle capable de prédire le risque cardio-vasculaire à partir d'une simple photographie de rétine. Nous ouvrons notre série "comprendre l'IA en médecine" avec le compte-rendu de la publication scientifique parue dans la revue Nature Biomedical Engineering en mars 2018.
Quel est le travail exécuté par les chercheurs? Quels sont leurs résultats? Comment peuvent-ils s'intégrer dans la médecine du quotidien? Réponse dans les lignes qui suivent.
LA METHODE DE L'ETUDE
La rétine change au cours de la vie. Elle se modifie en fonction de certains facteurs: âge, niveau de pression artérielle, tabagisme, taux de cholestérol, diabète, obésité…autant de facteurs de risque cardio-vasculaires.
Les chercheurs ont voulu montrer qu’un algorithme d’intelligence artificielle utilisant le « deep-learning » était capable d’extraire ces informations à partir d’une simple photographie de rétine.
Ils ont utilisé 2 bases de données issues de 2 études de surveillance médicale. La première est britannique. Elle a été conduite entre 2006 et 2010. Plus de 67 000 fonds d’oeil ont été faits parmi 500 000 personnes. Un questionnaire relevait les facteurs de risque cardio-vasculaire et les patients devaient mesurer leur pression artérielle par auto-mesure. La seconde est une étude américaine de suivi de la rétinopathie diabétique conduite entre 2007 et 2015 qui a permis de recueillir un peu moins de 250 000 fonds d'oeil.
QU'EST-CE QUE LE DEEP LEARNING?
En nous basant sur les explications fournies par les chercheurs de GOOGLE, essayons d'expliquer le deep-learning de façon intelligible pour le profane.
LES MOTS-CLEFS:
-Pas de programmation directe des solutions: l'ordinateur les retrouve lui-même
-Apprentissage à partir d'exemples
-Un algorithme est une succession de calculs mathématiques
-Le deep-learning est une succession d'équations mathématiques, fausses au début, progressivement corrigées par la machine elle-même
Le Deep learning ( apprentissage profond en français) est l’une des familles de technique d’apprentissage- machine. Avec cette méthode il n’est pas nécessaire de faire entrer manuellement les solutions dans la machine. Elle peut apprendre sans être programmée directement. C’est son grand avantage.
Il faut donc retenir que l'on ne donne pas les solutions d'avance à l'ordinateur. On lui montre des exemples, c'est-à-dire des images pour lesquelles la réponse est connue. Il va apprendre à partir de ces exemples.
Prenons le cas de la rétine de fumeur. Dans la base de données, tous les fumeurs sont identifiés.
N'oublions pas que les données utilisées proviennent de 2 études épidémiologiques médicales publiées il y a quelques années. Toutes les réponses étaient connues d'avance. Le but de l'étude était de voir si l'intelligence artificielle était capable de les retrouver.
Les chercheurs vont créer un algorithme qui recherche les fumeurs. Puis, ils montrent les photographies de rétine de fumeur à l'ordinateur. Lorsque l'ordinateur voit juste, on lui indique. Lorsqu'il voit faux, on lui indique également. L'ordinateur retient ce qu'il fait et mémorise les résultats de ses actions. Ainsi, après une phase d'entraînement, il est capable d'identifier les caractéristiques communes à toute rétine de fumeur. Il peut maintenant identifier un fumeur ou un non-fumeur à partir de n'importe quelle photographie de rétine.
Reconnaître une image : une opération mathématique
Comme toute programmation informatique, le deep-learning est une succession de calculs mathématiques. On parle de couches de calcul. Lorsque l'on montre les exemples à l'ordinateur, il exécute ces "couches de calcul" et ajuste lui-même les paramètres des équations mathématiques pour retrouver la bonne solution.
Pour désigner ces actions, les ingénieurs parlent de "réseau neuronal profond "( deep-neural network en anglais). Il est donc composé d’une séquence d’opérations mathématiques que l’on applique à une donnée d’entrée, par exemple la valeur du pixel d’une image. Le deep-learning est le procédé par lequel le modèle apprend à corriger ses erreurs pour arriver à une solution exacte.
Au début, le réseau neuronal est programmé au hasard. Puis, pour chaque image, la prédiction donnée par le modèle est comparée à un exemple dont le résultat exact est connu. Le modèle va alors progressivement corriger ses erreurs pour se mettre en adéquation avec l’exemple. Le processus est répété jusqu’à ce que les équations corrigées soient capables de trouver la solution exacte pour n’importe quelle image.
L’expression « apprendre de ses erreurs » n’a jamais été aussi vraie qu’avec le deep-learning !
QUELS SONT LES RESULTATS RETROUVES PAR LES CHERCHEURS ?
1. Retrouver la présence de facteurs de risque cardio-vasculaire
Les chercheurs ont utilisés les renseignements suivants présents dans les 2 bases de données: âge, genre, ethnie, l’indice de masse corporelle, la pression artérielle, le taux d’hémoglobine glyquée, le statut fumeur ou non.
INDICE DE MASSE CORPORELLE: à partir du poids et de la taille d'une personne, on mesure l'indice de masse corporelle (IMC) qui permet de savoir si il y a un surpoids ou au contraire un état trop maigre
HEMOGLOBINE GLYQUEE: mesure biologique obtenue par une prise de sang qui permet d'évaluer le taux de sucre sur les 3 derniers mois. Utilisé dans le suivi du diabète
Les chercheurs ont évalué la capacité de prédiction de leurs algorithmes en les comparant avec les résultats connus de la base de données. Le modèle d'intelligence artificielle s'avère très efficace pour prédire l’âge.
La pression artérielle systolique, l’indice de masse corporelle et l’hémoglobine glyquée sont également bien prédits mais le modèle est moins précis.
2. Calculer un risque d'événement cardio-vasculaire grave dans les 5 ans
Ensuite, les chercheurs ont entraîné le modèle à prédire la survenue d’un « accident cardio-vasculaire majeur » dans les 5 ans qui suivent le recueil des renseignements. Cette information n’était disponible que dans une seule des bases de données, UK Bio-bank. 631 patients, sur les 48 101 en ont été victimes. Les chercheurs ont donc voulu savoir si il aurait été possible de prévenir la survenue de ces accidents cardio-vasculaires. Pour cela ils ont calculé la probabilité de décès par le SCORE et l’ont comparé à la prédiction donnée par leur algorithme. Le SCORE était capable de prédire l’accident dans 72% des cas, l’algorithme dans 70% des cas. Les 2 méthodes apparaissent ainsi équivalentes.
QU'EST-CE QUE LE SCORE?
SCORE est l'acronyme de Systematic COronary Risk Evaluation (Evaluation du risque coronarien systématique). Il a été conçu sous l’égide de la Société Européenne de Cardiologie et publié en 2003. Il s'agit d'un outil de prévention médicale. Le médecin peut estimer le risque de décès par maladie cardio-vasculaire dans les 10 ans pour une personne donnée et proposer les mesures adaptées pour l'éviter. Il se présente comme un tableau à 4 entrées, un pour les hommes et un pour les femmes. On place le patient dans une case en fonction de son âge, de son taux de cholestérol, de sa pression artérielle systolique et du statut fumeur ou non fumeur. On lit le pourcentage de risque de décès par maladie-cardiovasculaire dans les 10 ans. Pour calculer le SCORE, il est donc nécessaire de réaliser une consultation médicale avec interrogatoire et une prise de sang.
Ci-dessous, tableau de calcul du SCORE
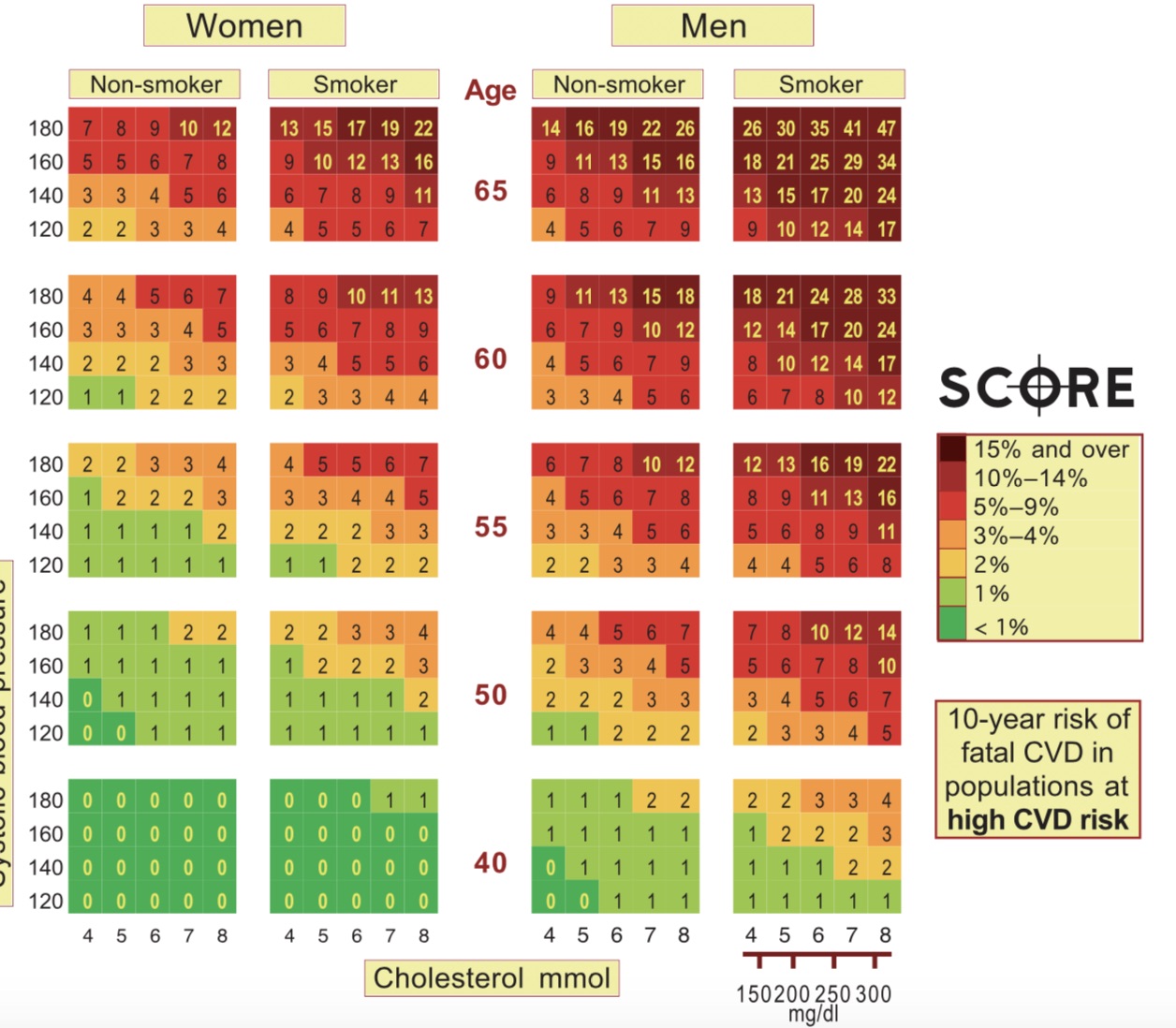
3. Quelles régions de la photographie de rétine ont-elles été utilisées par l'algorithme d'intelligence artificielle?
Les algorithmes sont des calculs mathématiques qui permettent de déterminer si une image de rétine est associée à un paramètre (ici, l’âge, la pression artérielle, l’hémoglobine glyquée, fumeur ou non fumeur, l’indice de masse corporelle). Mais les chercheurs n’indiquent pas par avance à la machine quelle région de la photographie il faut regarder pour déterminer le paramètre. En s’entraînant, elle va trouver par elle-même la région à regarder pour déterminer telle ou telle donnée.
Les chercheurs ont réussi à retrouver quelles régions ont été utilisées par la machine. Pour l’hémoglobine glyquée, il s'agit des pourtours vasculaires; pour le genre, du disque optique, des vaisseaux et de la macula. Pour la pression artérielle et l’indice de masse corporelle, il n’y avait en revanche pas de zone spécifique. Les chercheurs en déduisent que les effets de ces 2 paramètres sont diffus dans l’oeil.
Nous visualisons ainsi un peu mieux ce qu’est le deep-learning médical. La machine apprend réellement par elle-même puisqu’elle part d’équations mathématiques qui lui permettent de relier une image à un paramètre, un peu comme dans un exercice de langue étrangère où il faut relier une image avec le mot correspondant. Au début, elle commet beaucoup d'erreurs. Mais, au fur et à mesure de son entraînement, elle va être capable de réduire les erreurs et de cibler les zones de la rétine utiles pour répondre à la question posée.
Ci-dessous: les photographies de rétine utilisées dans l'étude
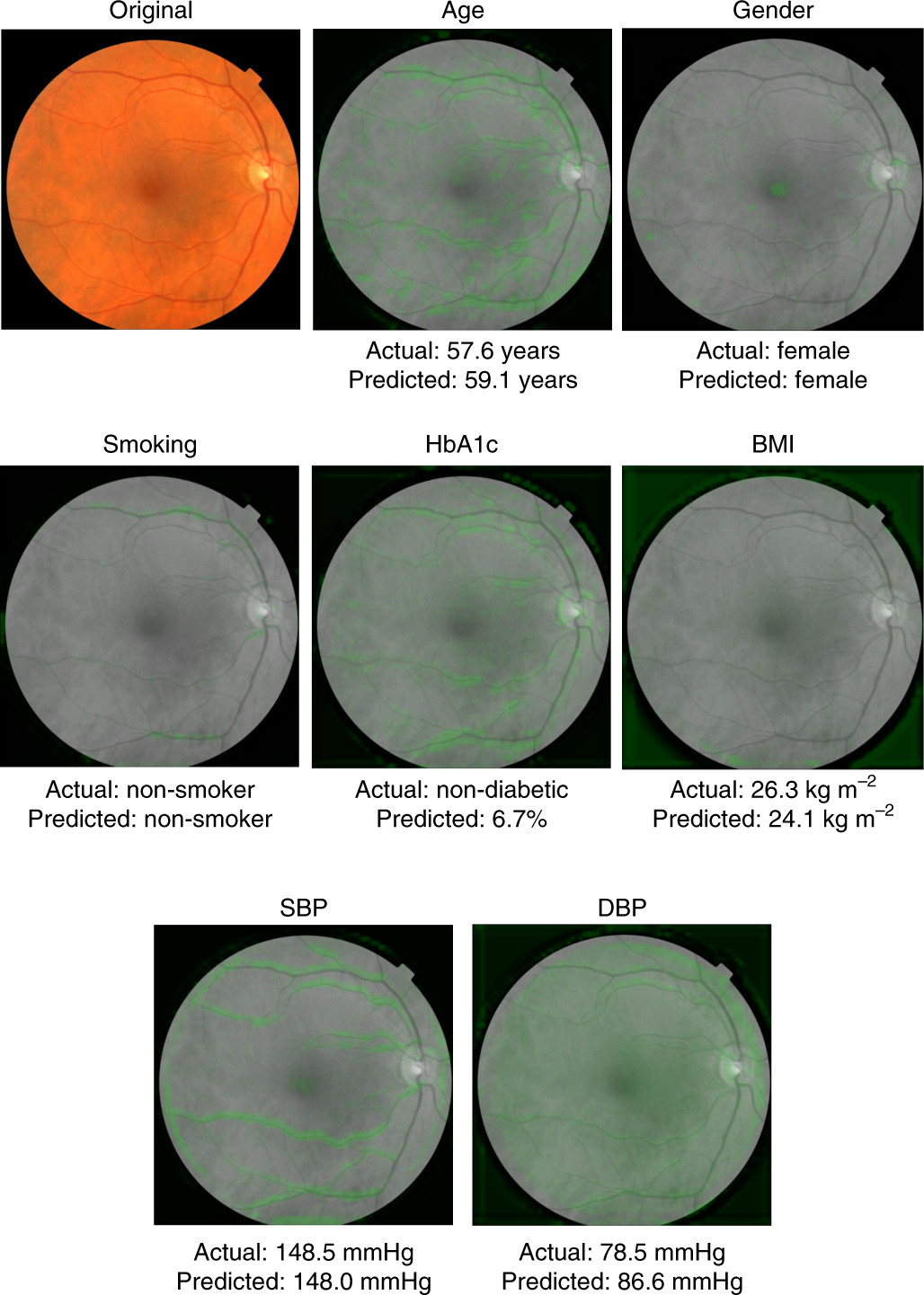
LA DISCUSSION DES AUTEURS. COMMENT INTERPRETENT-ILS LEURS RESULTATS?
Les auteurs se déclarent satisfaits des résultats obtenus. L’application du deep-learning à des images de fond d’oeil isolées a permis d’identifier plusieurs facteurs de risque cardio-vasculaire: âge, genre et pression artérielle systolique.
Ces éléments étant des composants essentiels des scores de calcul de risque de maladie cardio-vasculaire grave, les chercheurs ont émis l’hypothèse que leurs algorithmes pouvaient les calculer directement. Ceci semble confirmé par le résultat de leur deuxième expérience au cours de laquelle ils ont réussi à composer un algorithme de prédiction qui obtient la même performance que le score européen.
Mais les auteurs soulignent également une importante limite de leur travail. En effet, la taille des échantillons serait trop faible. Des effectifs plus grands seraient plus adaptés au deep-learning. Les résultats gagneraient en fiabilité.
QUELLE UTILITE DANS LA MEDECINE DU QUOTIDIEN? LE COMMENTAIRE DE MEDECINE-ET-ROBOTIQUE
Dans la pratique quotidienne, ce type d'intelligence artificielle apparaît être surtout un instrument de médecine de prévention. L'élément nouveau est de pouvoir retirer des renseignements précis sur une personne par une simple photographie de rétine, facile à obtenir. Si le coût de l'appareil est raisonnable, on pourrait imaginer une installation massive dans des structures collectives comme les centres de santé ou les hôpitaux, avec un résultat transmis au médecin traitant. Cette innovation pourrait donc élargir considérablement nos capacités de dépistage des maladies cardio-vasculaires.
La limite décrite par les auteurs appelle un commentaire. Selon eux, la taille des effectifs utilisés dans leur étude est trop faible. Ceci pourrait être un véritable obstacle pour le deep-learning en médecine.
En effet, pour l'épidémiologie médicale, les effectifs des 2 bases de données utilisées par les chercheurs sont importants. En dehors des grandes séries de suivi des maladies chroniques qui rassemblent les données de dizaines de milliers de personnes, il sera difficile d'obtenir davantage.
Si elle n'était pas surmontée, cette contrainte pourrait interdire à l'IA de se développer pleinement en médecine.
LES AUTRES ARTICLES DE LA RUBRIQUE
COMPRENDRE L’INTELLIGENCE ARTIFICIELLE EN MEDECINE N°2: DEPISTER LE MELANOME
COMPRENDRE L'IA EN MEDECINE N°3: DIAGNOSTIQUER DES METASTASES DE CANCER DU SEIN
PRESENTATION DE L'AUTEUR DU BLOG
Pascal Meyer,
Médecin des hôpitaux,
Anesthésiste-Réanimateur, Intensiviste- Réanimateur
Exerce au sein du Service de Réanimation de l'hôpital de FONTAINEBLEAU (77)
QUELQUES ETAPES CLEFS DE MON PARCOURS PROFESSIONNEL
Etudes: faculté de médecine de Créteil ( 94)
Concours de l'Internat: 1998
Internat d'Anesthésie-Réanimation Chirurgicale, Centre Hospitalier Universitaire de Lille (59): 1998-2003
Chef de Clinique-Assistant des Hôpitaux, Réanimation Médicale, Centre Hospitalier Universitaire Saint-Antoine, Paris: 2003-2005
Praticien Hospitalier : 2006
POURQUOI CE BLOG?
C'est en recherchant des solutions innovantes pour les actes techniques difficiles en réanimation que je me suis tourné vers la robotique. J’ai progressivement élargi mon centre d’intérêt vers l’intelligence artificielle, un domaine intimement lié à la robotique.
Les métiers de la santé sont appelés à se transformer à mesure que robots et systèmes d’intelligence artificielle s'intégreront dans les activités du quotidien. La question du remplacement du travail humain est posée, transformant le sujet technologique en problème de société.
Il m’est alors apparu que la maîtrise des 2 technologies était fondamentale pour le futur des professionnels de santé, médecins et para-médicaux.
J'ai ainsi démarré l’étude des applications médicales de la robotique et de l'intelligence artificielle dans l’objectif de préparer ma propre formation continue.
Ce BLOG rassemble des articles rédigés à partir de mes sources documentaires et de mes notes personnelles. J’espère qu’il sera utile au plus grand nombre.